Devaansh Gupta
I am a Research Engineer at Essential AI, working on code pre-training.
Previously, I had the privilege of working with Prof. Aditya Grover on diffusion-based language models on my masters thesis at UCLA. We proposed d1 - the first framework to develop reasoning dLLMs.
I have also held research assistant positions at multiple top-tier universities, working closely with outstanding faculty mentors!
Email / CV / GitHub / Twitter / Google Scholar / LinkedIn
Research
I am interested in developing foundation models end-to-end. I strongly believe that pre-training with intent makes post-training a breeze for LLMs, and am working towards that eventuality.

Publications
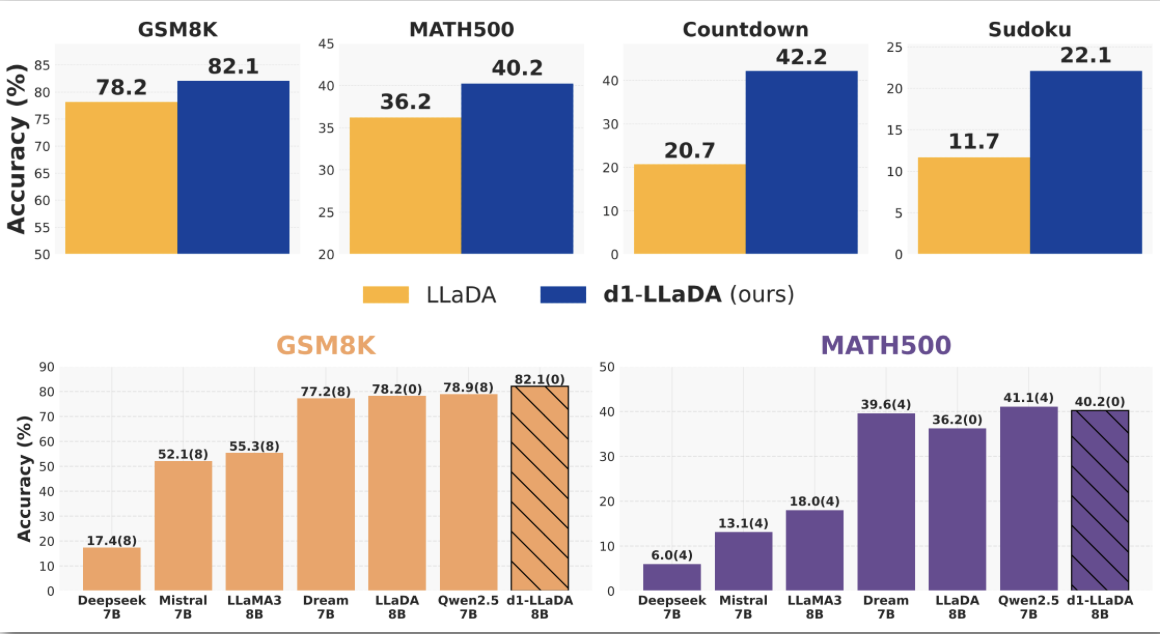
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
NeurIPS (Spotlight), 2025
project / arxiv / code
We propose a two-stage framework, d1, that employs masked SFT on distilled reasoning traces, followed by a variant of GRPO for dLLMs, called diffu-GRPO, to convert prertrained dLLMs into storng reasoning models. With this, we demonstrate strong reasoning performance against AR models, and faster convergence rate than conventional GRPO!
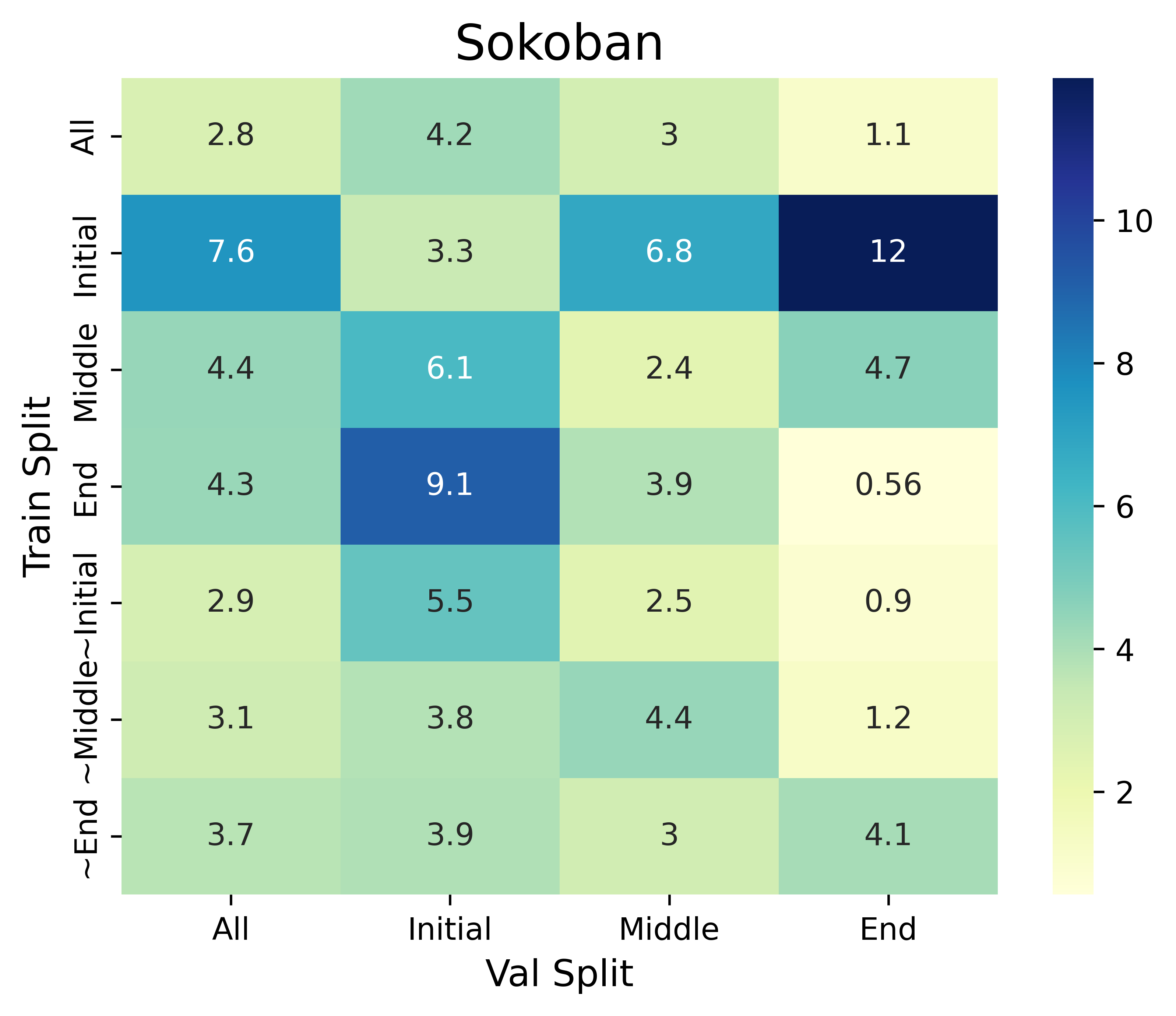
A Training Data Recipe to Accelerate A* Search with Language Models
Findings of EMNLP 2024, 2024
We study an important aspect of LM-based tree-search algorithms, the heuristic, by disentangling the search process from heuristic learning. Subsequently, we develop a mathematical model to select training data in accordance with both algorithms, achieving significant speed-ups in finding solutions to classical planning problems.
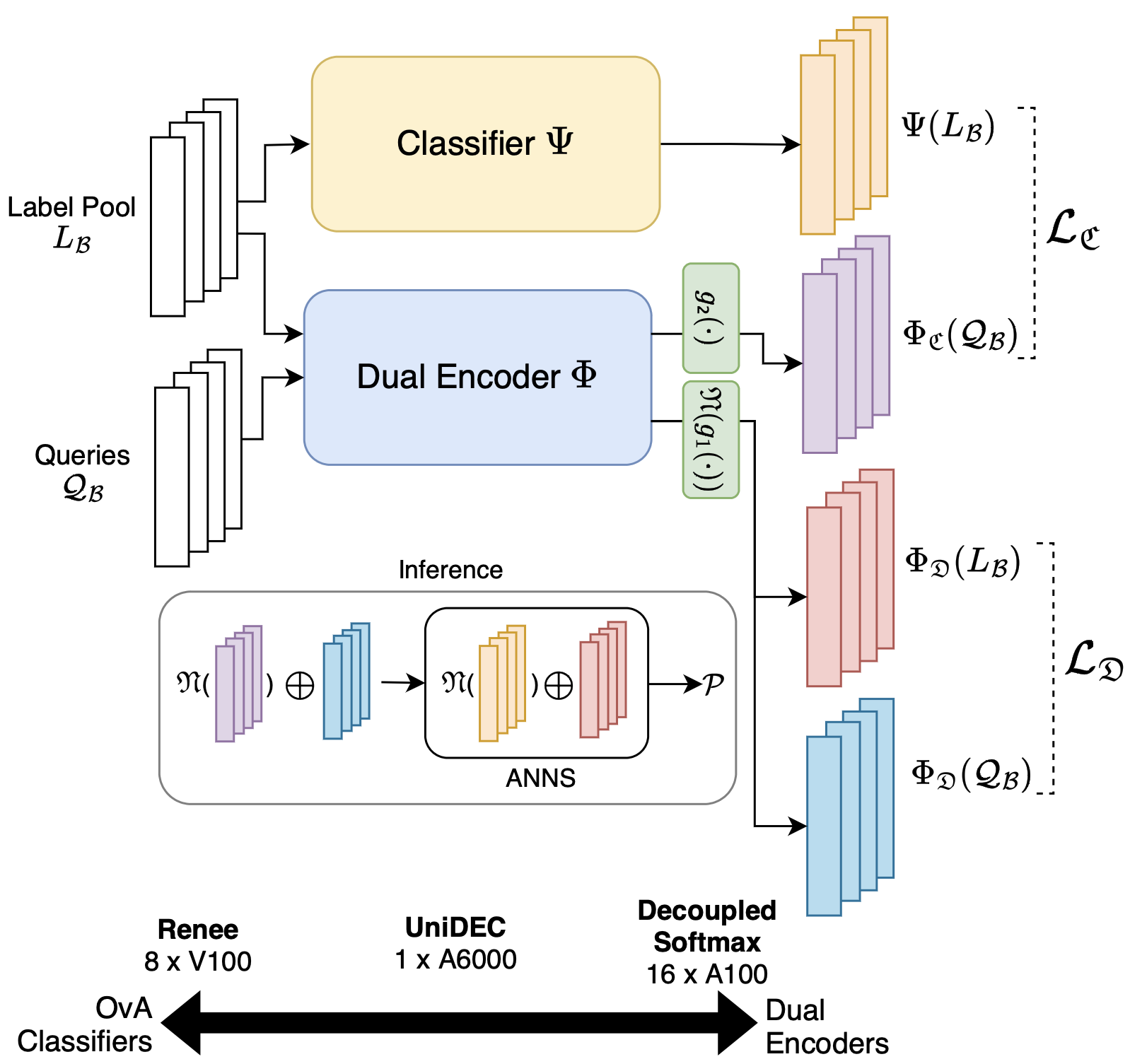
UniDEC: Unified Dual Encoder and Classifier Training for Extreme Multi-label Classification
WWW, 2024
We propose a “Pick-Some-Labels” reduction for multilabel classification - a relaxation of the conventional “Pick-All-Labels” reduction. This is coupled with Supervised Contrastive Learning to develop a framework - UniDEC - to concurrently train a dual encoder and classifier. UniDEC achieves state-of-the-art performance on a single GPU, rivalling baselines which require 8-16 GPUs.
Learning label-label correlations in Extreme Multi-label Classification via Label Features
KDD, 2024
We take a data-centric approach to short-text extreme classification and propose data augmentation methods, LabelMix and Gandalf, which are derived from label-to-label correlations in the training set. We demonstrate their effects on previous architectures and forward the SOTA by imbuing effective inductive biases that were missing in previous models.

CLIPTrans: Transferring Visual Knowledge with Pre-trained Models for Multimodal Machine Translation
ICCV, 2023
project / arxiv / code
We hypothesise that machine translation can be improved by introducing a visual component. For this, we design a new architecture, CLIPTrans, a combination of the multimodal CLIP and the multilingual mBART. We demonstrate significant improvements over the previous MMT SOTA, especially across low-resource languages.
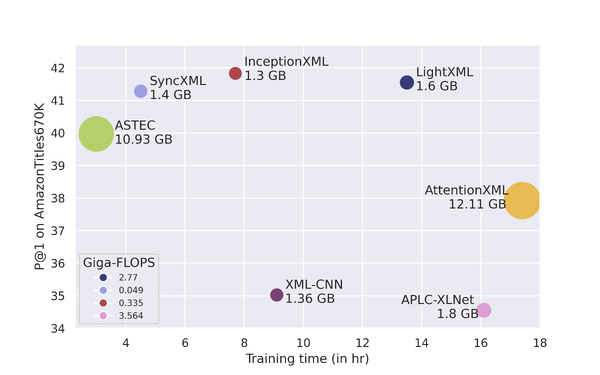
InceptionXML: A Lightweight Framework with Synchronized Negative Sampling for Short Text Extreme Classification
SIGIR, 2023
arxiv / code
We developed a lightweight convolutional encoder, InceptionXML, in a dynamic negative sampling framework, SyncXML, for short-text extreme classification. InceptionXML in SyncXML beat the previous SOTA on a multitude of performance and parametric metrics.